

Qwen2-Audio是什么?
Qwen2-Audio是由阿里通义团队推出的大型音频语言模型系列,它能够接受音频信号输入,进行音频分析或直接文本响应,支持语音聊天和音频分析两种交互模式,并且提供了预训练模型Qwen2-Audio-7B和聊天模型Qwen2-Audio-7B-Instruct的版本。

Qwen2-Audio的主要特点
- 语音聊天:用户可以使用语音向音频语言模型发出指令,无需通过自动语音识别(ASR)模块。
- 音频分析:该模型能够根据文本指令分析音频信息,包括语音、声音、音乐等。
- 多语言支持:该模型支持超过8种语言和方言,例如中文、英语、粤语、法语、意大利语、西班牙语、德语和日语。
Qwen2-Audio的模型效果
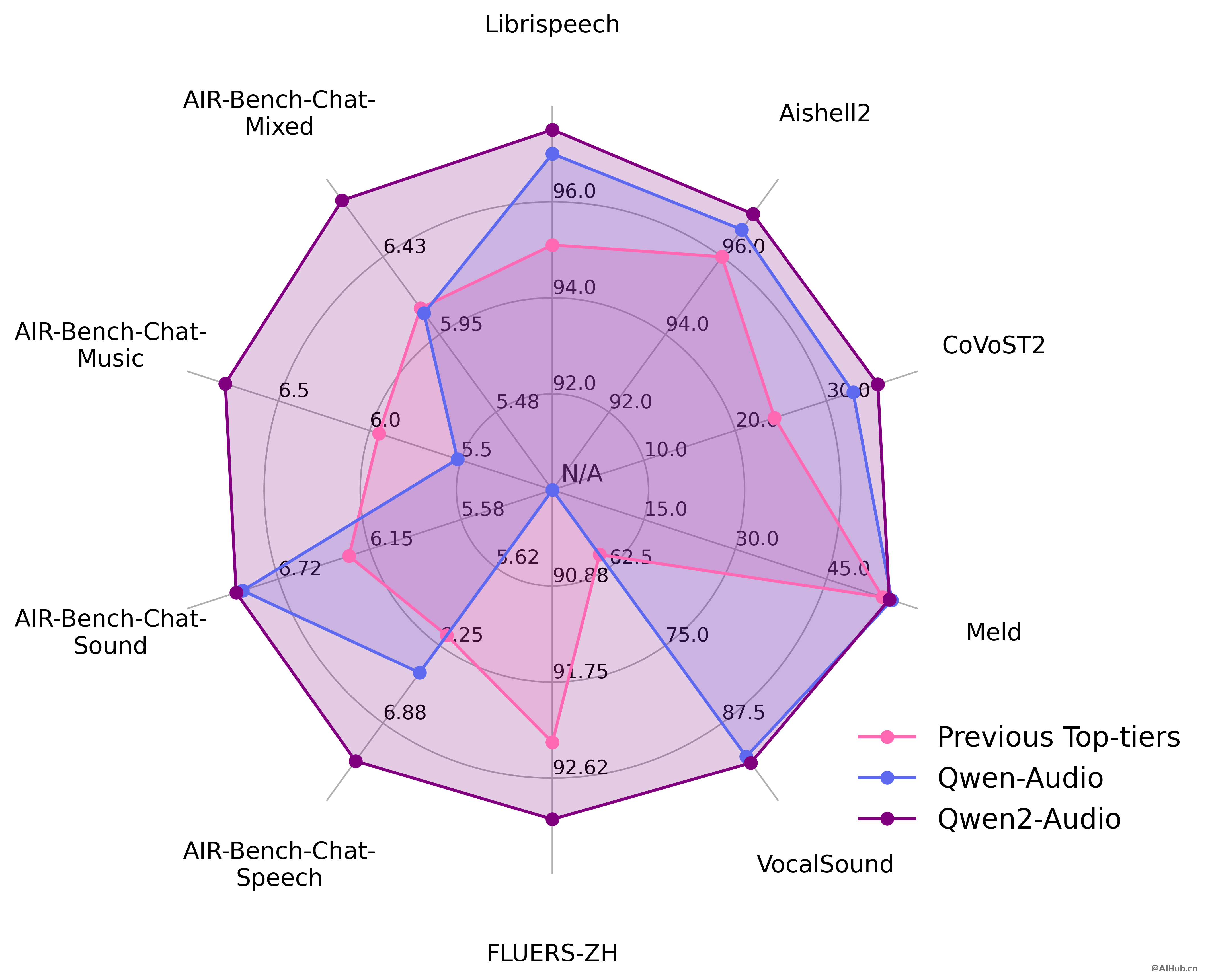
官方在一系列基准数据集上进行了实验,包括 LibriSpeech、Common Voice 15、Fleurs、Aishell2、CoVoST2、Meld、Vocalsound 以及 AIR-Benchmark,下面我们将展示一张图表来说明 Qwen2-Audio 相对于竞争对手的表现。在所有任务中,Qwen2-Audio 都显著超越了先前的最佳模型或是 Qwen-Audio。
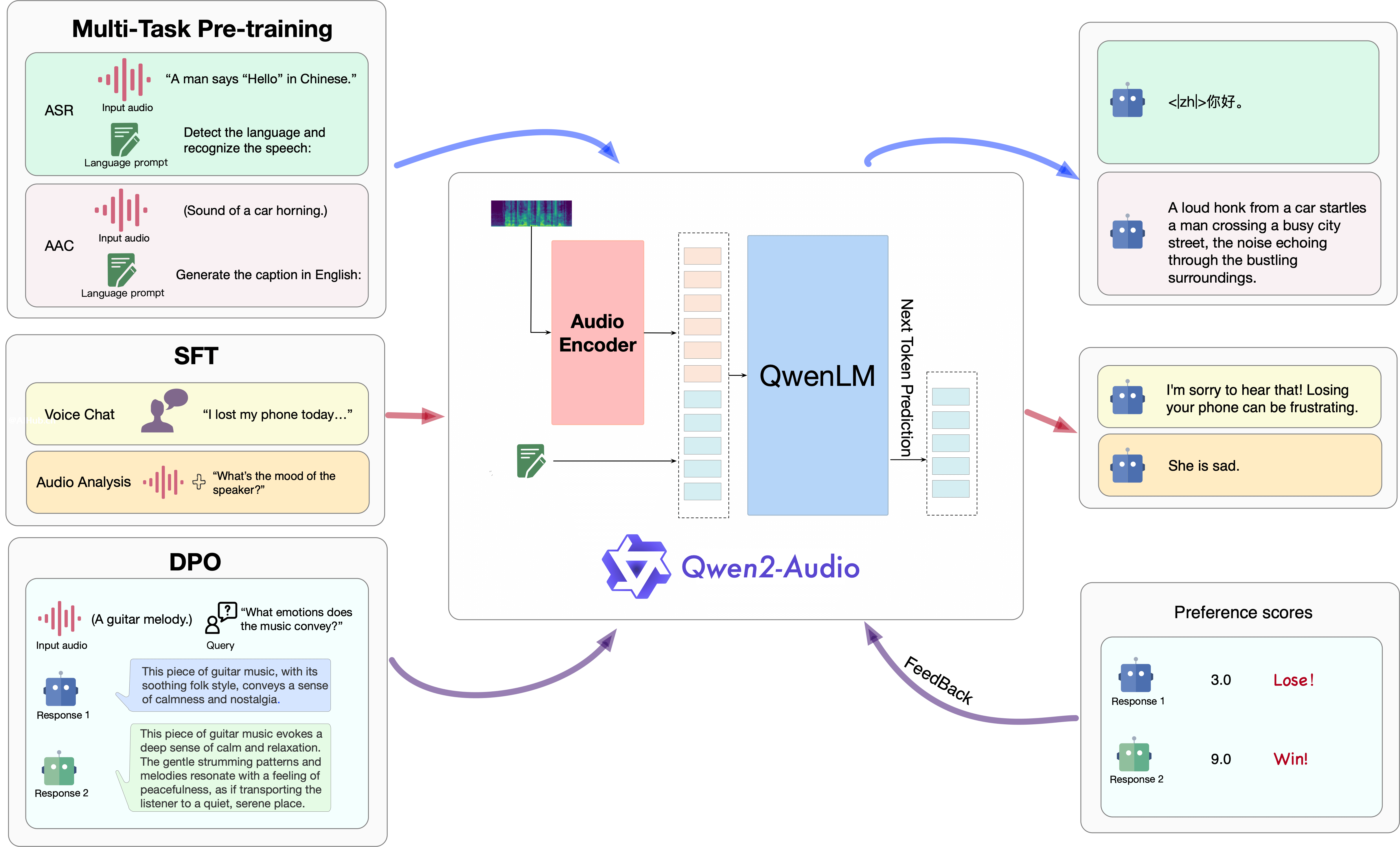
Qwen2-Audio的模型结构与训练范式
Qwen2-Audio使用 Qwen 语言模型和音频编码器这两个基础模型,接着依次进行多任务预训练以实现音频与语言的对齐,以及 SFT 和 DPO 来掌握下游任务的能力并捕捉人类的偏好。
如何使用Qwen2-Audio?
Qwen2-Audio团队在 Hugging Face 和 ModelScope 上开源了 Qwen2-Audio-7B 以及 Qwen2-Audio-7B-Instruct,并且搭建了一个在线体验demo,相关链接如下:
- Qwen2-Audio在线体验:https://huggingface.co/spaces/Qwen/Qwen2-Audio-Instruct-Demo
- Qwen2-Audio项目地址:https://qwenlm.github.io/zh/blog/qwen2-audio
- Qwen2-Audio GitHub地址:https://github.com/QwenLM/Qwen2-Audio
- Qwen2-Audio论文地址:https://arxiv.org/pdf/2407.10759
- Qwen2-Audio MODELSCOPE地址:https://modelscope.cn/organization/qwen
据官方透露,在不久的将来,Qwen2-Audio团队计划在更大的预训练数据集上训练出更优秀的 Qwen2-Audio 模型,使该模型能够支持更长的音频(超过30秒),并且还将构建更大规模的 Qwen2-Audio 模型,用于研究音频语言模型的扩展定律。

©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
