

Qwen2.5-Omni是什么?
Qwen2.5-Omni是阿里巴巴通义团队推出的一款全模态大语言模型。它能够处理多种输入形式,包括文本、音频、图像和视频,并生成相应的输出。该模型采用Thinker-Talker双核架构,其中Thinker模块负责理解和处理多模态信息,Talker模块则将这些理解转化为自然语音输出。Qwen2.5-Omni在语音识别、翻译、语音生成和多模态理解等方面表现出色,具备高效的实时处理能力,适用于多个应用场景。
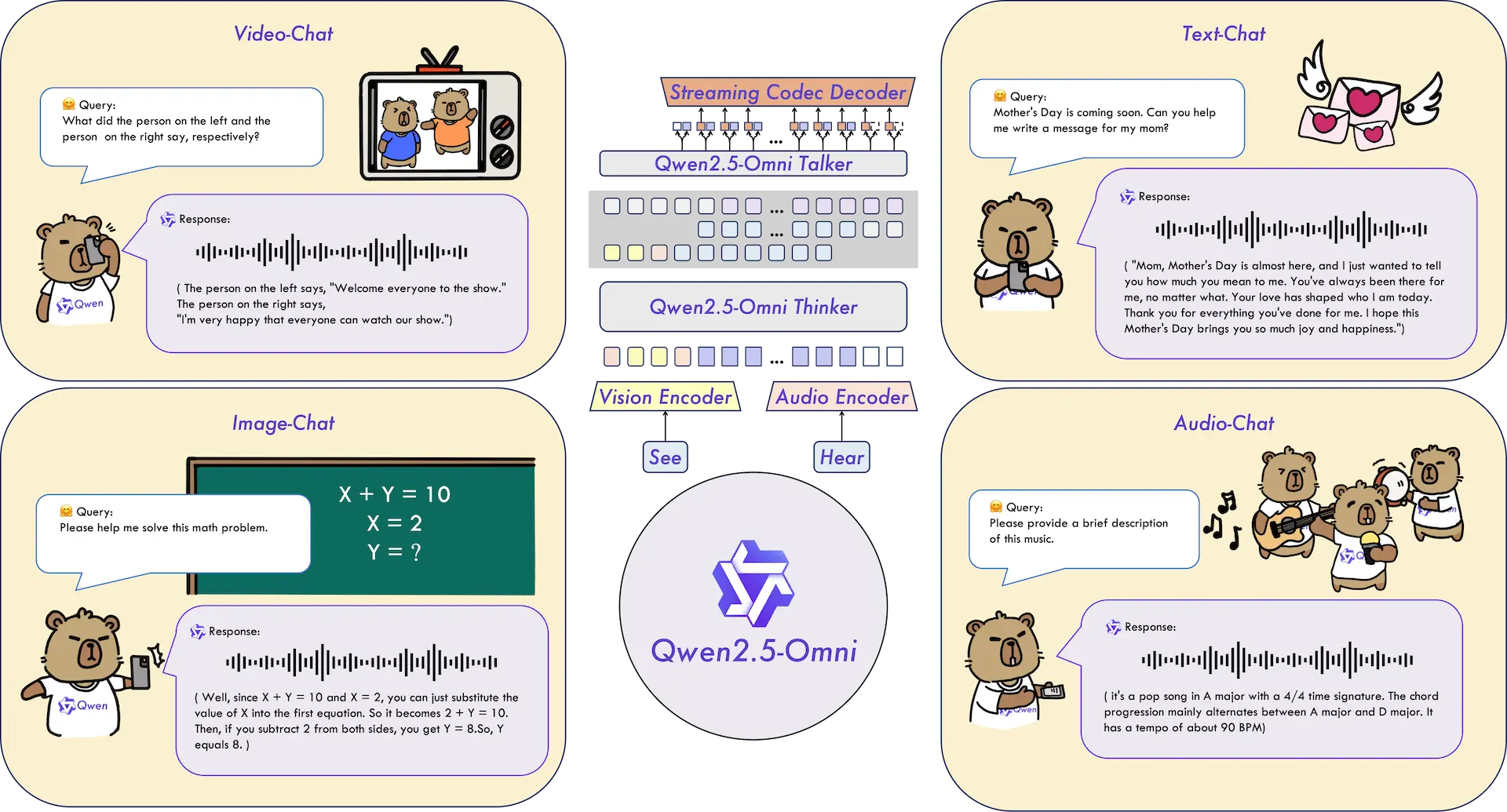
Qwen2.5-Omni的主要特点
- 全模态处理能力:支持文本、音频、图像和视频等多种输入形式,能够同时处理和理解不同类型的信息。
- 双核架构:采用Thinker-Talker双核架构,Thinker模块负责处理和理解输入信息,Talker模块将理解结果转化为自然语音输出。
- 实时交互能力:支持音视频的实时处理和生成,能够快速响应输入并生成输出。
- 自然语音生成:在生成语音时,Qwen2.5-Omni能够确保语音的自然流畅,超越了许多现有的模型。
- 多模态性能优化:在多个基准测试中,Qwen2.5-Omni在音频理解和多模态处理方面表现出色,能够有效应对复杂任务。
- 强大的语音指令理解能力:在理解语音命令和进行语音指令跟随方面具有卓越的表现,能够处理复杂的指令并执行任务。
Qwen2.5-Omni的模型性能
Qwen2.5-Omni在包括图像,音频,音视频等各种模态下的表现都优于类似大小的单模态模型以及封闭源模型,例如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro。在多模态任务OmniBench,Qwen2.5-Omni达到了SOTA的表现。此外,在单模态任务中,Qwen2.5-Omni在多个领域中表现优异,包括语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然听感)。

如何体验Qwen2.5-Omni ?
- 在线体验:https://chat.qwenlm.ai/
- 模型地址:
- Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
- ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
- GitHub仓库:https://github.com/QwenLM/Qwen2.5-Omni
- 技术论文:https://github.com/QwenLM/Qwen2.5-Omni/assets/Qwen2.5_Omni.pdf
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
