

Qwen2.5-Coder是什么?
Qwen2.5-Coder是由阿里巴巴最新推出的开源代码生成模型,本次一共有0.5B、3B、14B和32B四个版本,Qwen2.5-Coder 支持40多种编程语言的模型,能够处理多种编程任务,尤其在代码生成、修复和推理方面具有显著优势。
根据阿里公布的测试数据显示,32B指令微调模型在 EvalPlus、LiveCodeBench、Spide和Bird-SQL的测试中,成为开源模型中性能排名第一,超过GPT-4o、Claude 3.5 Sonnet两款闭源模型。综合能力和GPT-4o几乎一样,成为目前最强的开源代码模型。
Qwen2.5-Coder的主要特性
- 强大的代码能力:Qwen2.5-Coder-32B-Instruct 被认为是目前开源代码模型中的领先者,具有与 GPT-4o 相媲美的能力。它在多个流行的代码生成基准(如 EvalPlus、LiveCodeBench、BigCodeBench)中取得了优异成绩,展示了出色的代码生成、修复和推理能力。
- 多编程语言支持:该模型支持超过40种编程语言,展现出在多种语言中的出色表现,尤其是在 Haskell、Racket 等语言中表现突出,适用于多语言的代码修复和生成任务。
- 代码修复与推理:除了代码生成,Qwen2.5-Coder-32B-Instruct 还能够高效修复代码错误,提升编程效率。此外,它在代码推理方面也表现强劲,可以预测代码的输入输出关系。
- 多样化的模型尺寸:Qwen2.5-Coder 提供了0.5B、1.5B、3B、7B、14B、32B六种不同尺寸的模型,满足不同开发者在资源和计算能力上的需求。无论是在小型设备还是大型服务器上,开发者都能找到适合的模型。
- 人类偏好对齐:该模型的开发注重与人类偏好的对齐,并且通过特定的评测(如Code Arena)测试,表现出了良好的对齐性。
- 开源与许可:Qwen2.5-Coder 模型采用 Apache 2.0 许可证,确保了开源社区的参与和扩展能力。
Qwen2.5-Coder的性能评测
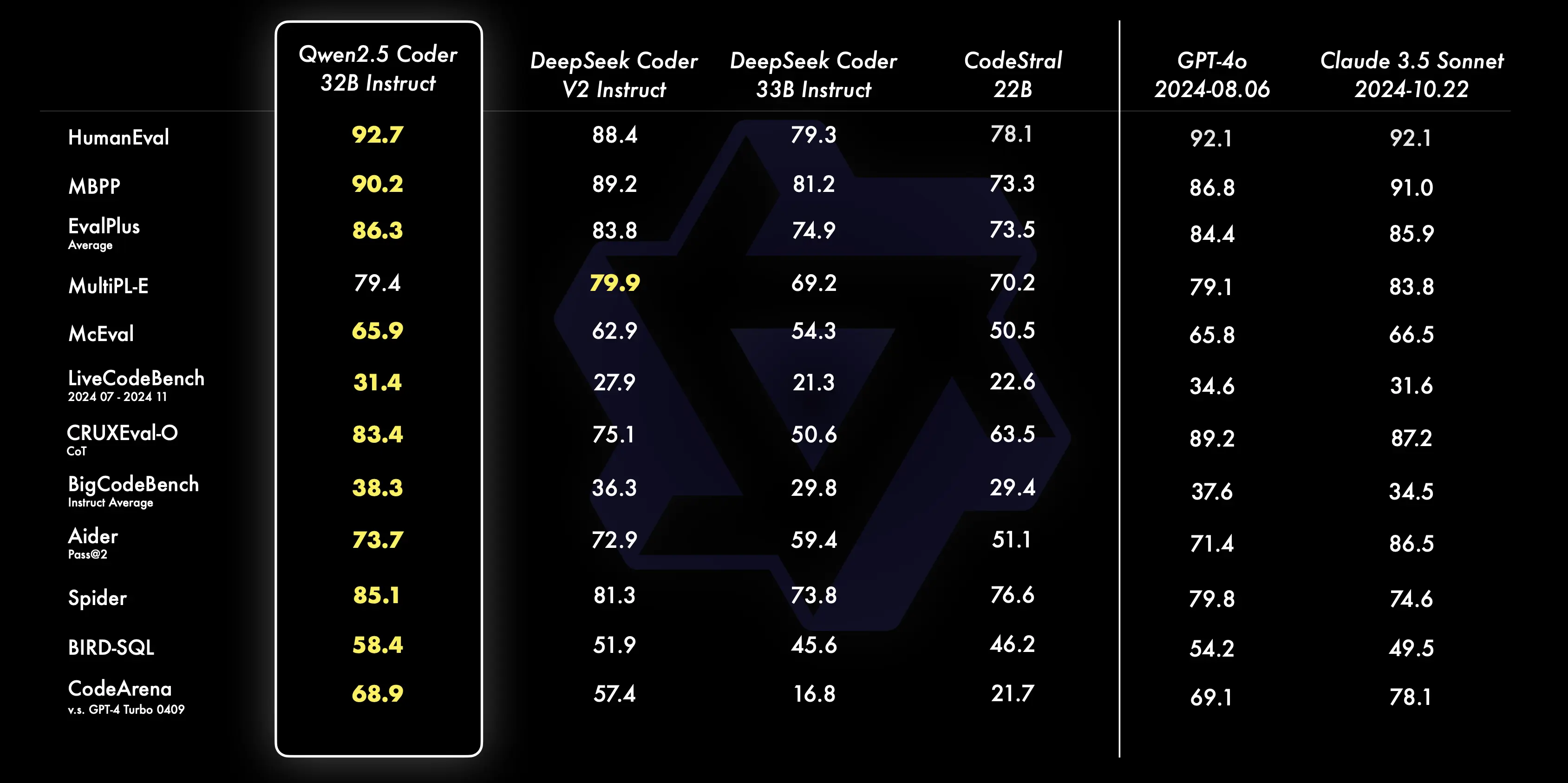
- 代码生成:Qwen2.5-Coder-32B-Instruct 作为本次开源的旗舰模型,在多个流行的代码生成基准(如EvalPlus、LiveCodeBench、BigCodeBench)上都取得了开源模型中的最佳表现,并且达到和 GPT-4o 有竞争力的表现。
- 代码修复:代码修复是一个重要的编程能力。Qwen2.5-Coder-32B-Instruct 可以帮助用户修复代码中的错误,让编程更加高效。Aider 是流行的代码修复的基准,Qwen2.5-Coder-32B-Instruct 达到 73.7 分,在 Aider 上的表现与 GPT-4o 相当。
- 代码推理:代码推理是指模型能否学习代码执行的过程,准确地预测模型的输入与输出。上个月发布的 Qwen2.5-Coder-7B-Instruct 已经在代码推理能力上展现出了不俗的表现,32B 模型的表现更进一步。
- 多编程语言:智能编程助手应该熟悉所有编程语言,Qwen2.5-Coder-32B-Instruct 在 40 多种编程语言上表现出色,在 McEval 上取得了 65.9 分,其中 Haskell、Racket 等语言表现令人印象深刻,这得益于我们在预训练阶段独特的数据清洗和配比。
如何使用Qwen2.5-Coder?
- 开源地址:https://github.com/QwenLM/Qwen2.5-Coder
- huggingface:https://huggingface.co/spaces/Qwen/Qwen2.5-Coder-Artifacts
- 在线demo:https://huggingface.co/spaces/Qwen/Qwen2.5-Coder-demo

©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。