

继各类单一模态输入的多模态语言模型后,新加坡国立大学的华人团队最近开源了全能多模态模型NExT-GPT。该模型支持任意模态的输入和输出,可以实现文本、图像、语音和视频之间的自由转换,是第一个实现从任一模态到任一模态转换的通用多模态系统。
项目地址:https://next-gpt.github.io
代码地址:https://github.com/NExT-GPT/NExT-GPT
论文地址:https://arxiv.org/abs/2309.05519
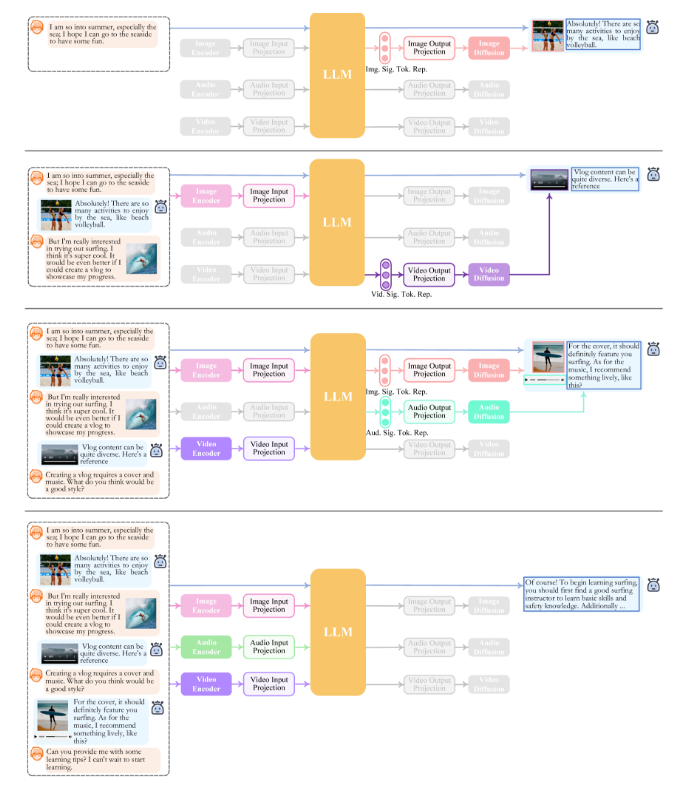
NExT-GPT的优势在于它实现了真正意义上的任意模态输入到任意模态输出,而不是仅仅支持某一种固定的输入输出模式。用户可以随意组合不同模态进行查询,NExT-GPT都可以进行理解并用请求的模态形式给出响应。这充分模拟了人类处理信息的能力,是向通用人工智能目标迈进的重要一步。
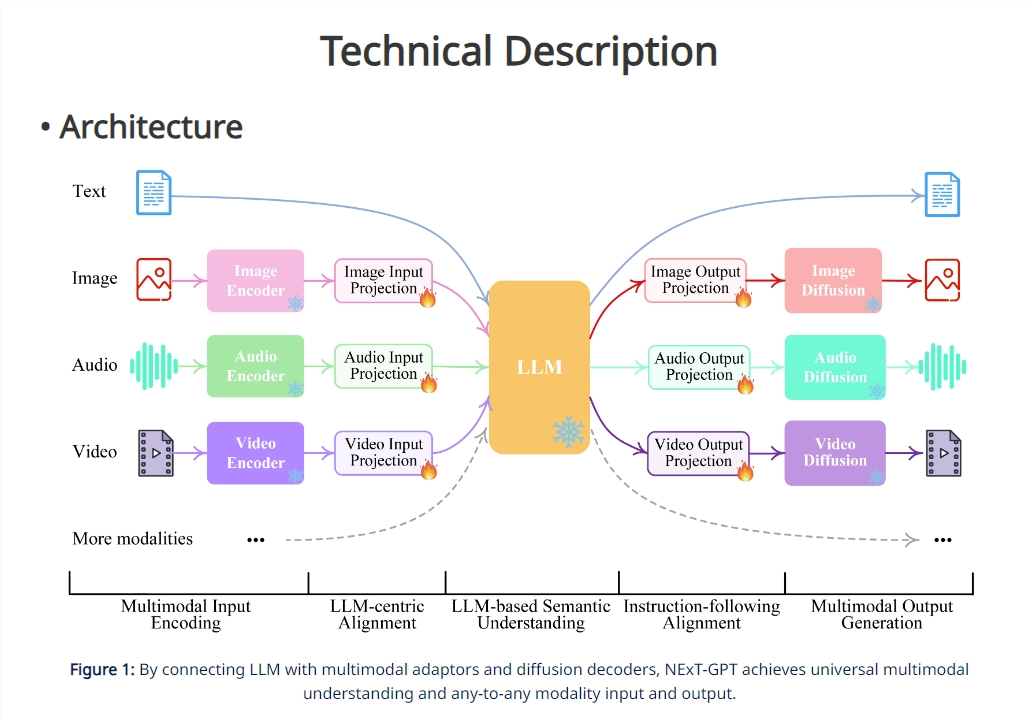
在技术上,NExT-GPT并没有创新算法,而是站在巨人的肩膀上,通过组合优化利用现有的各类开源模块实现全能目标。具体来说,模型包含三个层次:第一,使用各类模态编码器对输入进行编码;第二,语言模型负责复杂推理;第三,解码器生成各种模态输出。
NExT-GPT的独特之处在于实现了模态特征表达的端到端对齐训练,以及针对多模态输出做了指令微调。这保证了在输入理解、内部推理和输出生成各层次间特征的有效传递,从而实现了优秀的多模态理解与生成能力。
虽然NExT-GPT目前还有待进一步扩展,但其展示了构建通用多模态系统的可能性,为人工智能研究提供了宝贵的借鉴。后续工作可以考虑扩展更多模态,使用更大规模的语言模型基座,以及改进多模态生成策略等。
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
