

Llama 3.2是什么?
Llama 3.1是Meta最新推出的开源大语言模型,包括90B和11B两种参数规格的视觉大语言模型,还有能在设备端本地运行的1B和3B轻量级纯文本模型,包括预训练和指令调整版。1B和3B模型支持128K tokens上下文,适配高通和联发科硬件,并针对Arm处理器做了优化。

Llama 3.2的主要特性
- 轻量级文本模型:1B 和 3B 模型专为移动和边缘设备设计,具备较小的模型尺寸,但依然提供强大的文本生成和处理能力。支持 128K tokens 的大上下文处理,适合文本总结、重写和指令跟随等任务。
- 视觉模型:11B 和 90B 模型能够处理图像理解任务,支持多模态任务(图像与文本结合),例如文档理解、图像生成描述、视觉推理和目标识别。该模型通过图像编码器与语言模型集成,能够处理复杂的视觉问题。
- 本地处理与隐私保护:Llama 3.2 模型可以在设备上本地运行,极大减少了数据传输延迟,并增强了数据隐私保护。这使其特别适用于需要高效处理和高隐私要求的场景,例如手机、平板和物联网设备。
- 开放和可定制性:Llama 3.2 强调开放性,允许开发者自由下载、修改和定制模型,适应各种不同的应用需求。用户可以根据需要使用开源工具进行微调,如 torchtune(微调)和 torchchat(部署)。
- 广泛硬件支持:Llama 3.2 对 Qualcomm、MediaTek 和 Arm 等移动硬件平台进行了优化,使其可以在绝大多数现代设备上高效运行。此外,还支持 AMD、NVIDIA、Intel、AWS、Google Cloud 等主流云平台和硬件。
- Llama Stack 开发工具:Llama 3.2 提供了一整套工具(Llama Stack),包括 CLI、API 和 Docker 容器,帮助开发者在不同的环境中轻松部署模型,支持从单节点到云端的多种部署方式。
- 高效模型压缩与知识蒸馏:Llama 3.2 通过模型修剪和知识蒸馏技术来压缩模型,减小了模型的尺寸而不牺牲其性能。这一优化使得 1B 和 3B 模型可以在资源有限的设备上高效运行。
- 多语言支持:Llama 3.2 在多语言生成和工具调用方面表现出色,能够处理多种语言的文本生成和理解任务,适用于全球化应用场景。
- 安全性增强:Llama 3.2 配备了 Llama Guard,这是一套保护系统,能够过滤不适当的输入和输出,确保模型在文本和图像处理时保持安全与负责。
Llama 3.2的性能评测
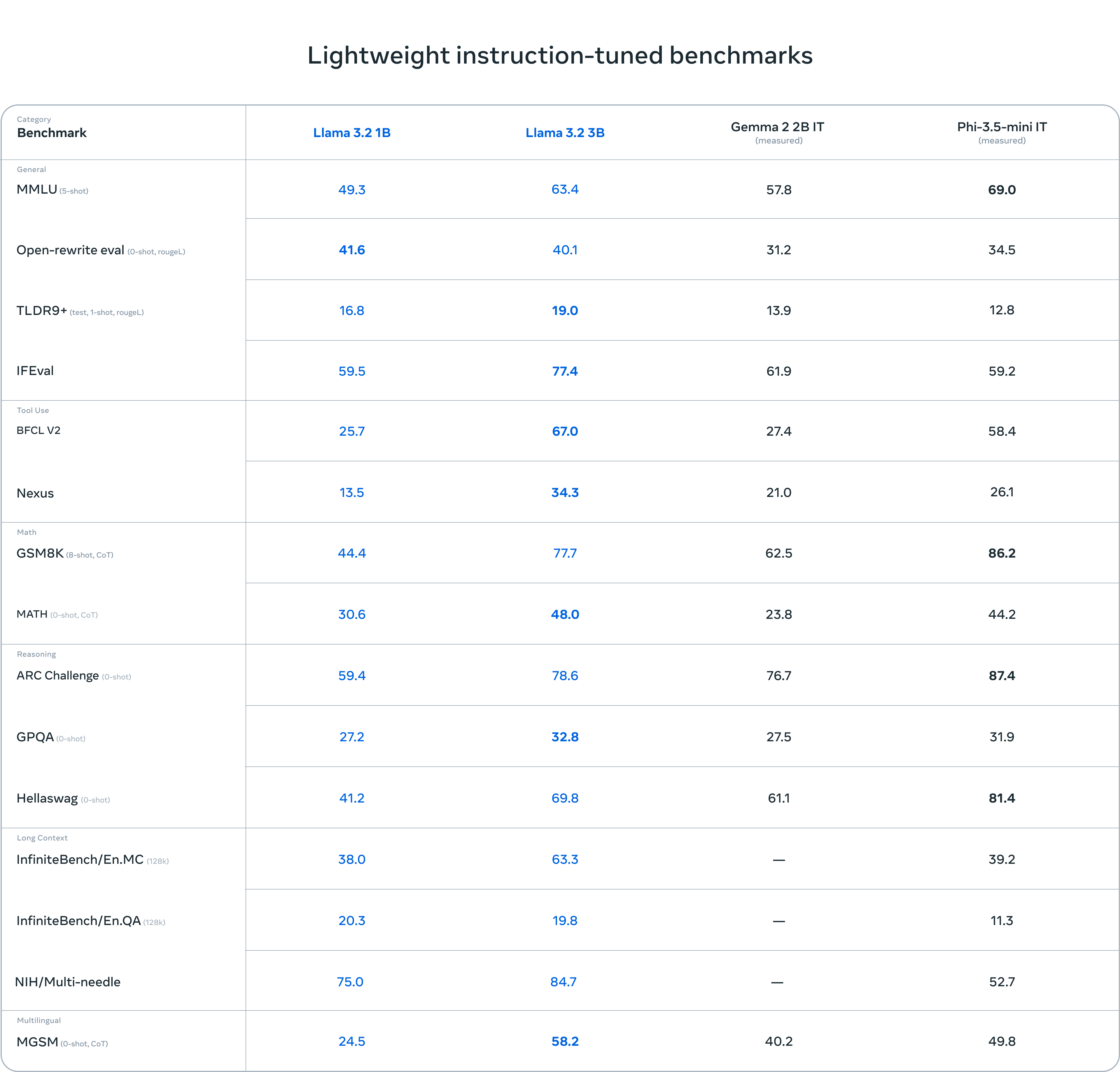
3B模型在遵循指令、总结、快速重写和工具使用等任务上的表现优于Gemma 2 2.6B、Phi 3.5-mini模型。1B模型的表现媲美Gemma。
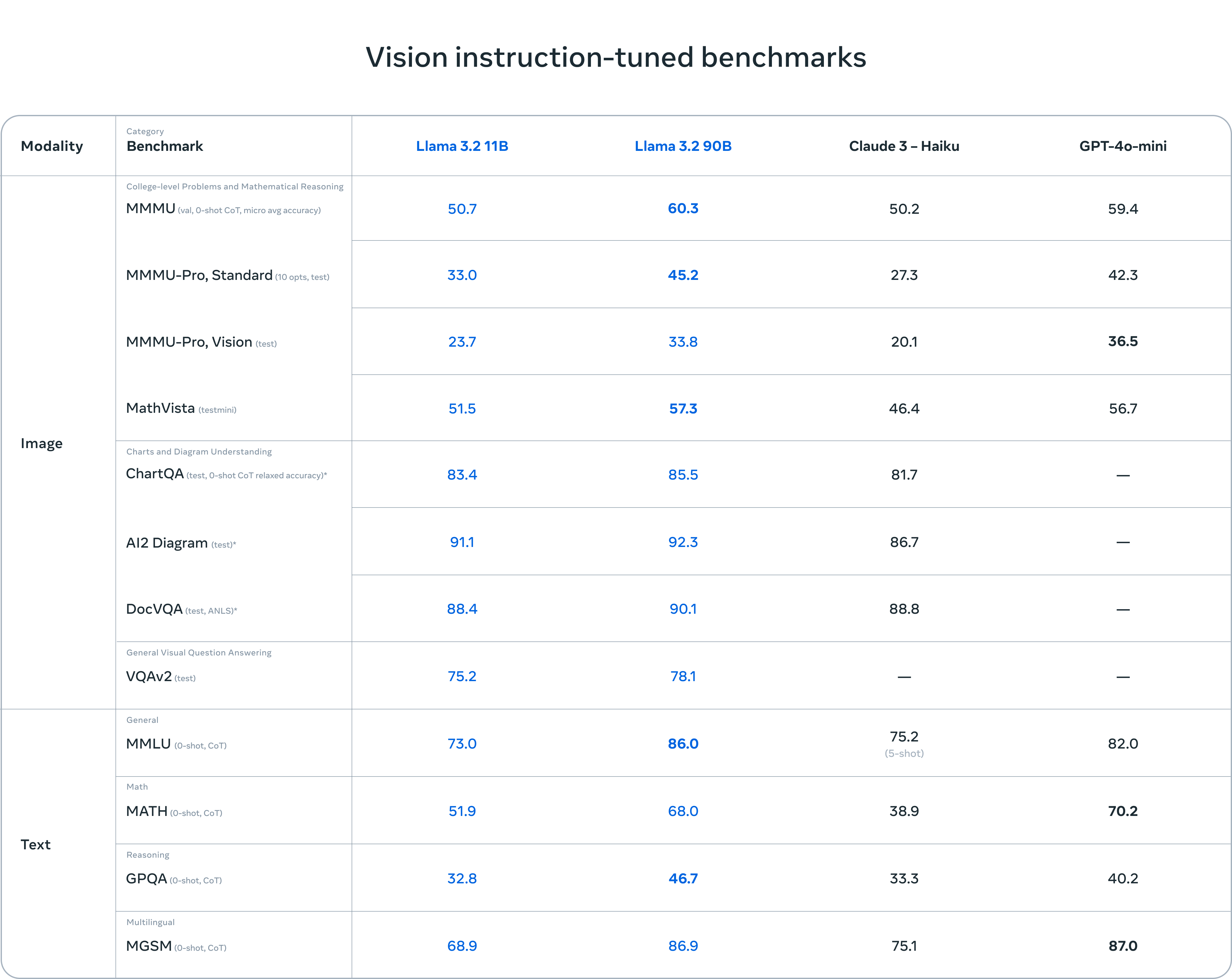
90B和11B视觉模型是其相应文本模型的直接替代品,同时在图像理解任务上的表现优于封闭模型,如Claude 3 Haiku、GPT-4o mini。
如何使用Llama 3.2?
1、企业和开发者:
Llama 3.2 现已于 Meta 官网和 Hugging Face 开放下载,也可以在其合作伙伴平台上进行开发,包括 AMD、AWS、Databricks、Dell、Google Cloud、Groq、IBM、Intel、Microsoft Azure、NVIDIA、Oracle Cloud、Snowflake 等。
- Llama 3.2模型下载:https://www.llama.com/
- Llama 3.2博客文章:https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
- Llama 3.2 HuggingFace模型下载:https://huggingface.co/collections/meta-llama/
- GitHub项目:https://github.com/meta-llama/llama-models
2、个人用户
Llama 3.2已经上线到Meta AI平台,如有兴趣可前往体验。
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
