

Kimi-Audio是什么?
Kimi-Audio 是由kimi开源的通用音频基础模型,支持语音识别、音频理解、音频转文本和语音对话等多种任务。它采用集成式架构,包括音频分词器、音频大模型和音频去分词器,能够高效处理多种音频任务。该模型使用了约1300万小时的多语言、多场景音频数据进行预训练,并通过监督微调进一步提升性能。在十多项基准测试中,Kimi-Audio 总体性能排名第一,尤其在自动语音识别、音频理解、音频到文本聊天和语音对话等任务中表现出色。
Kimi-Audio 的模型架构
为实现 SOTA 级别的通用音频建模, Kimi-Audio 采用了集成式架构设计,包括三个核心组件 —— 音频分词器(Audio Tokenizer)、音频大模型(Audio LLM)、音频去分词器(Audio Detokenizer)。
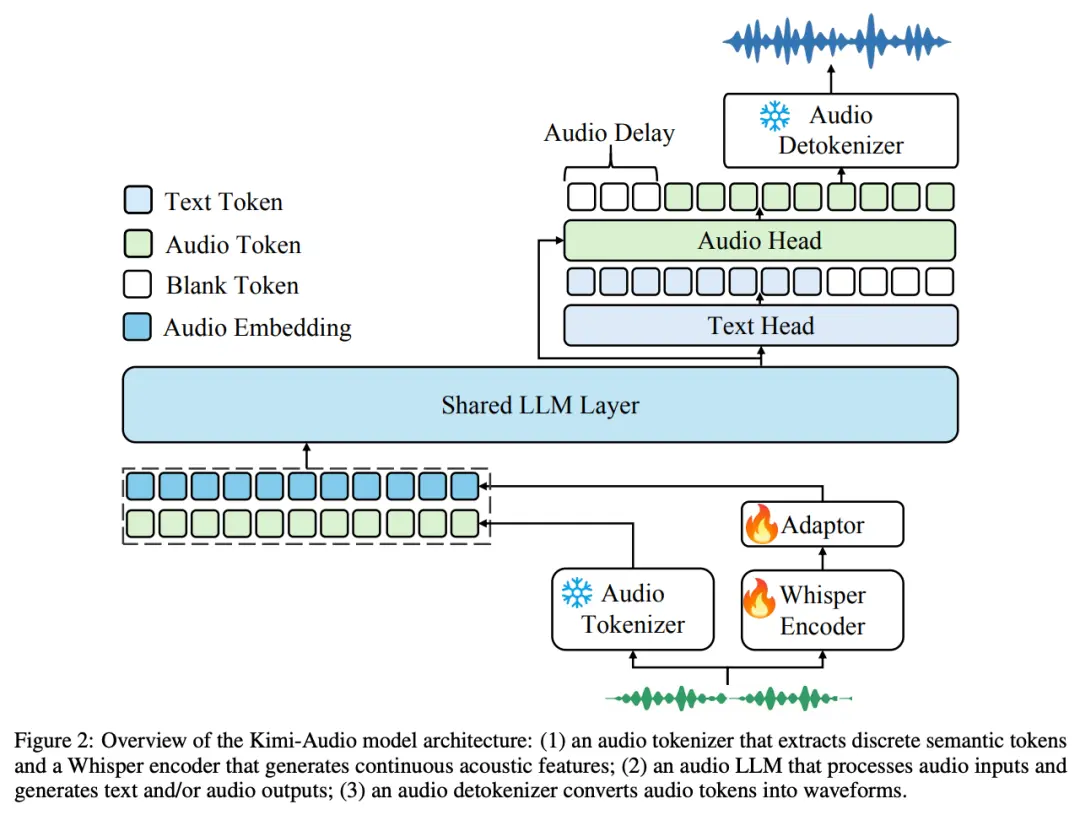
- 音频分词器(Audio Tokenizer):将输入音频转化为离散语义 token 和连续声学向量,帧率为 12.5Hz,结合语义压缩表示与声学细节。
- 音频大模型(Audio LLM):基于共享 Transformer 层,处理多模态输入,后期分为文本和音频生成的两个并行输出头。
- 音频去分词器(Audio Detokenizer):使用流匹配方法,将离散语义 token 转化为连贯音频波形,生成高质量语音。
Kimi-Audio的模型表现
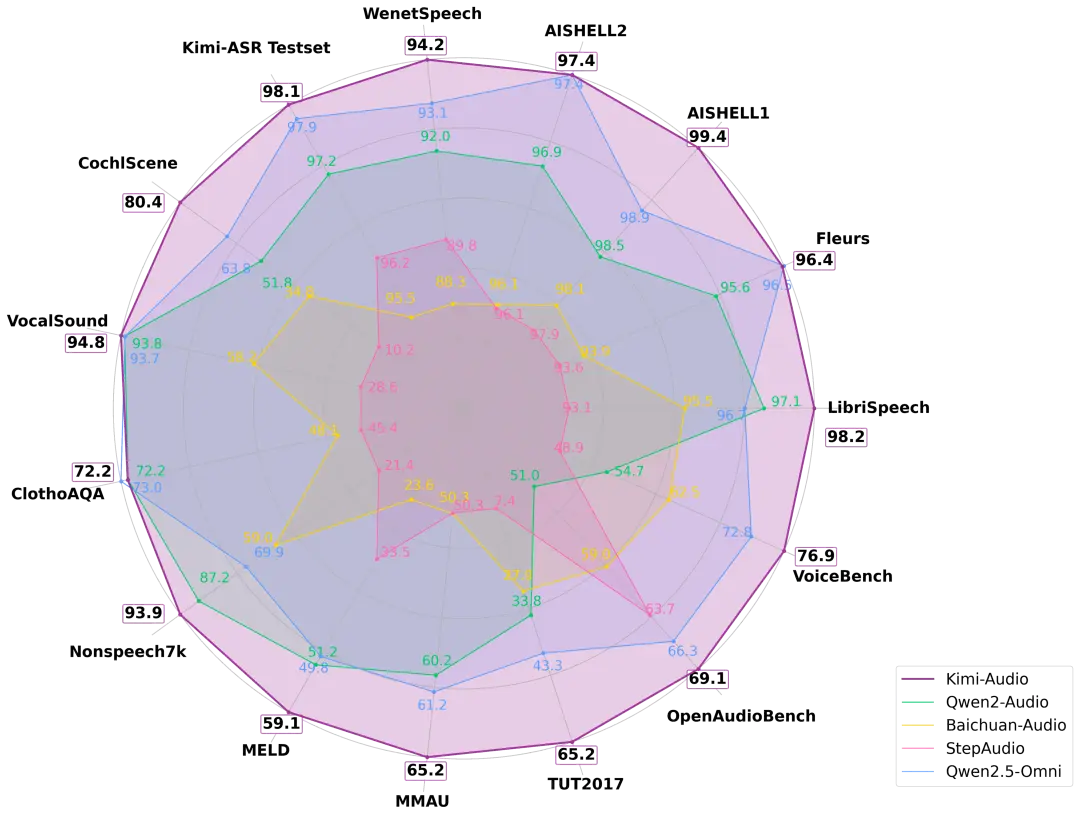
Kimi-Audio 在十多个音频基准测试中实现了最先进的 (SOTA) 性能,总体性能排名第一。
在 LibriSpeech ASR 测试上,Kimi-Audio 的 WER 仅 1.28%,显著优于其他模型。VocalSound 测试上,Kimi 达 94.85%,接近满分 。MMAU 任务中,Kimi-Audio 摘得两项最高分;VoiceBench 设计评测对话助手的语音理解能力,Kimi-Audio 在所有子任务中得分最高,包括一项满分。
Kimi-Audio的项目信息
目前,模型代码、模型检查点以及评估工具包已经在 Github 上开源。
- GitHub项目链接:https://github.com/MoonshotAI/Kimi-Audio
- 技术报告:https://github.com/MoonshotAI/Kimi-Audio/blob/master/assets/kimia_report.pdf
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
