

Hunyuan-Large是什么?
Hunyuan-Large是腾讯混元最新开源的 MoE 大模型,Hunyuan-Large 拥有 3890 亿总参数量、520 亿激活参数量,并支持 256K 上下文长度,是目前业界参数规模最大、性能领先的开源 MoE 模型。
基于 MoE(Mixture of Experts)结构的优越性,混元 Large 在推理速度和参数规模之间取得平衡,显著提升了模型的处理能力。测试结果显示,Hunyuan-Large 在 CMMLU、MMLU、CEval、AGIEval 等多学科评测集以及中英文 NLP 任务、代码、数学等9大维度表现出色,超越 Llama3 和 Mixtral 等主流开源模型。

Hunyuan-Large的模型特性
- 高质量合成数据:通过加强合成数据的训练,Hunyuan-Large 可以学习更丰富的表征,处理长上下文输入,并更好地泛化到未见过的数据。
- KV 缓存压缩:利用分组查询关注 (GQA) 和跨层关注 (CLA) 策略,大幅减少 KV 缓存的内存使用量和计算开销,从而提高推理吞吐量。
- 特定专家学习率缩放:为不同专家设置不同的学习率,以确保每个子模型都能有效地从数据中学习并提高整体性能。
- 长文本处理能力:预训练模型支持高达 256K 的文本序列,而指导模型支持高达 128K 的文本序列,从而显著增强了处理长文本任务的能力。
- 广泛的基准测试:在各种语言和任务中进行广泛的实验,以验证浑源大数据的实际有效性和安全性。
Hunyuan-Large的专项能力
高质量文本创作:Hunyuan-Large可提供高质量写作、润色、总结、创意生成等文本创作能力。

数学能力:提供数学计算表格公式及图表生成等能力。

知识问答:模型具有较好的通用语义理解和知识储备,可回复用户知识性提问。

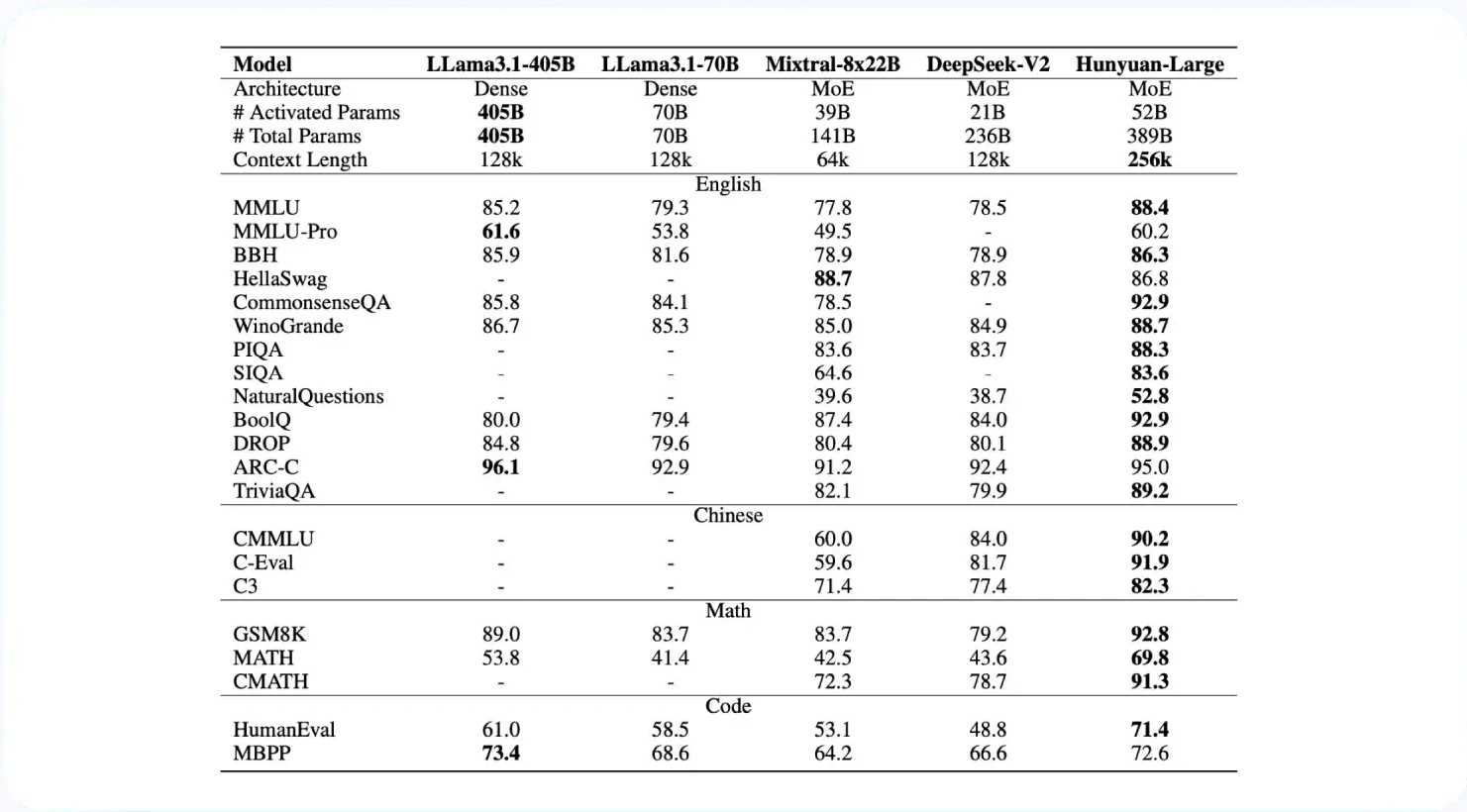
Hunyuan-Large的性能评估
Hunyuan-Large在与业界开源的DeepSeek-V2 、Llama3.1-70B、Llama3.1-405B以及Mixtral-8x22B的对比中,在CMMLU、MMLU、CEval等多学科综合评测集、中英文NLP任务、代码和数学等9大维度全面领先,处于行业领先水平。
如何使用Hunyuan-Large?
- 在线体验Hunyuan-Large :https://huggingface.co/spaces/tencent/Hunyuan-Large
- GitHub代码地址:https://github.com/Tencent/Tencent-Hunyuan-Large
- Huggingface模型仓库:https://huggingface.co/tencent/Tencent-Hunyuan-Large
- Hunyuan-Large技术报告:https://arxiv.org/abs/2411.02265
- 腾讯云开发平台:https://cloud.tencent.com/document/product/851/112032
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
