

Gemini 2.0是什么?
Gemini 2.0 是 Google 最新推出的多模态人工智能大模型,支持处理文本、图像、音频和视频等数据类型。相比 1.0,2.0 在多模态方面实现突破,不仅支持图像、视频和音频输入,还支持原生图像和音频输出,并可调用谷歌搜索、代码及第三方函数,显著提升模型的灵活性和扩展性。它具备自主代理能力和增强的推理功能,已深度集成至 Google 应用中,适合专业人士、创作者及普通用户,助力提升效率、优化任务流程,标志 AI 技术迈入新阶段。
此次发布的是 Gemini 2.0 系列模型中的第一个模型:Gemini 2.0 Flash 实验版。

Gemini 2.0的功能特性
- 多模态输入与输出:Gemini 2.0 支持同时处理文本、图像、音频和视频等多种输入类型,不仅能理解这些不同形式的数据,还能生成图像和音频内容,扩展了 AI 在跨媒体任务中的应用范围。
- 自主代理功能:Gemini 2.0 能够代替用户执行复杂的任务和决策。它不仅能进行信息查询,还能自动化处理多步骤任务,如撰写报告、整理数据、进行决策分析等,大大减少了人工干预。
- 增强推理和规划能力:相比于前版本,Gemini 2.0 在推理和问题解决上更加深入,能够处理复杂的多步骤任务,提供详细的思考过程和分步执行方案。这使其能够在面对复杂问题时,提前规划并给出更为精确的解决策略。
- 灵活的工具调用:Gemini 2.0 具备强大的扩展性,可以调用 Google 自家的工具(如 Google 搜索、lens、地图等)以及第三方工具或函数,极大地增强了其灵活性和功能。
- 深度集成于 Google 生态:Gemini 2.0 深度集成到 Google 的多项服务中,如 Google 搜索、Google Chrome 浏览器以及 Google 助手等,这使得用户可以直接在这些平台上利用 Gemini 2.0 完成任务。
- 灵活的扩展性和可定制性:Gemini 2.0 允许开发者调用外部工具、函数和 API,具有很高的定制化和扩展性。这意味着企业和开发者可以根据自身需求,将 Gemini 2.0 集成到工作流程中,定制专门的功能。
Gemini 2.0的性能评测
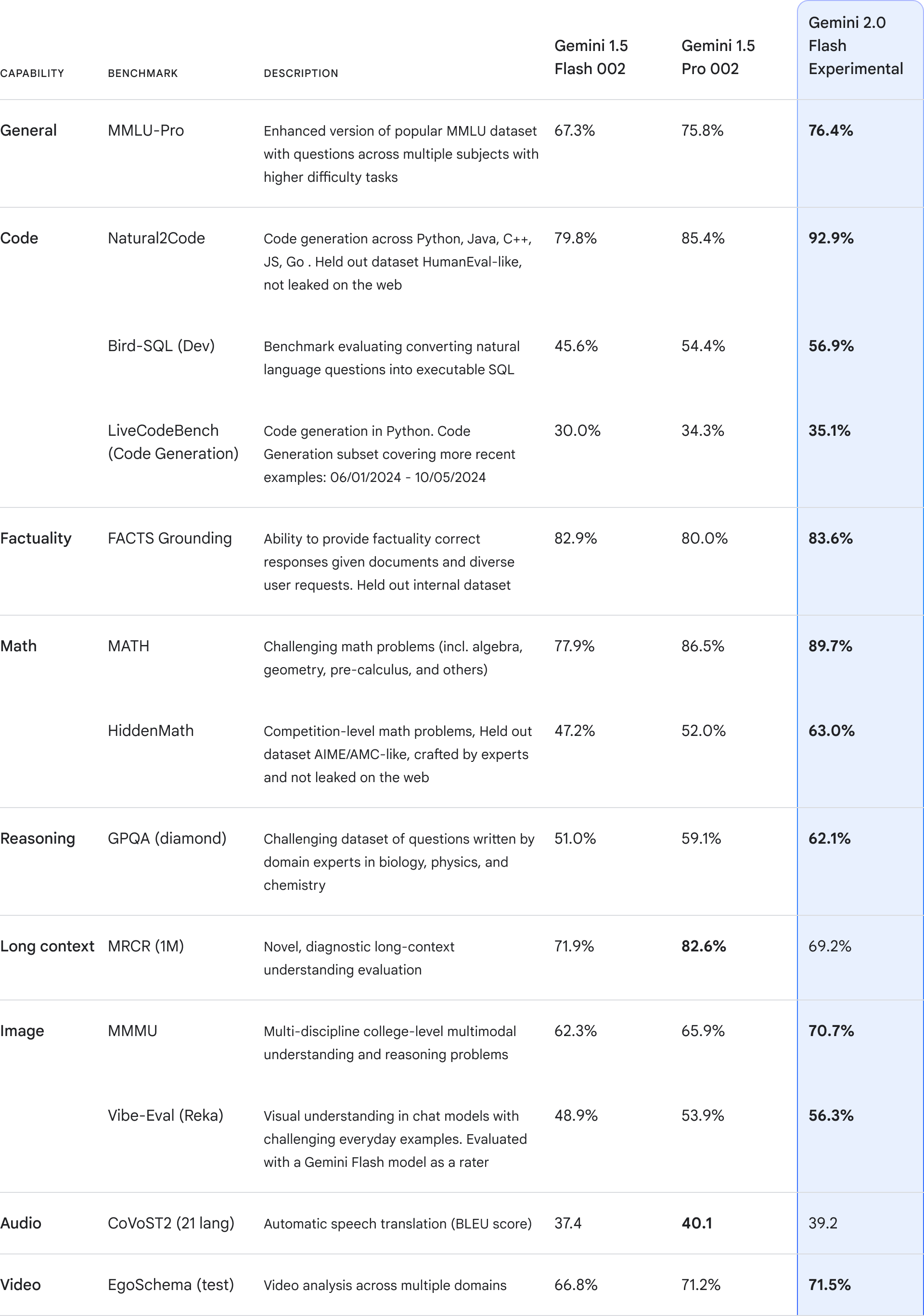
在关键基准测试中,Gemini 2.0 Flash 甚至超过了 Gemini 1.5 Pro,速度是后者的两倍。
如何使用Gemini 2.0?
目前发布的是Gemini 2.0 Flash版本,已上线到Google开发者平台和Gemini应用中。
- 开发人员:可以通过 Google AI Studio 和 Vertex AI 在 Gemini API 中开始使用该模型进行构建。
- 普通用户:全球的Gemini和Gemini Advanced 用户可以在网页版模型下拉菜单中选择 Gemini 2.0,试用聊天优化版本。
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
