

Emu3是什么?
Emu3是由北京智源研究院推出的原生多模态世界模型,旨在简化和提升多模态任务的处理能力。多模态任务指的是同时处理不同类型的数据(如图像、视频、文本等)。与依赖扩散模型(如 Stable Diffusion)或组合架构(如 CLIP 与大型语言模型结合)的传统方法不同,Emu3 采用了 next-token 预测技术,将图像、文本、视频转化为离散的 token,并使用单一的 Transformer 模型进行训练。
Emu3只基于下一个 token 预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成,官方宣称实现图像、文本、视频大一统。
Emu3的功能特性
- 图像生成:Emu3 通过预测视觉 token 来生成高质量图像,支持灵活的分辨率和风格,不再需要扩散模型,生成过程更为高效。
- 视频生成:与依赖噪声生成视频的扩散模型不同,Emu3 通过预测视频序列中的下一个 token 来生成视频,使整个过程更加简洁高效。
- 视频预测:Emu3 能够对视频进行延续预测,模拟现实世界中的环境、人物和动物行为,展现强大的物理世界模拟能力。
- 视觉-语言理解:Emu3 展现了强大的视觉和语言感知能力,可以对图像进行详细描述,并提供连贯的文本回复,而无需依赖 CLIP 和预训练的大型语言模型。
- 多模态整合:Emu3 通过将文本、图像和视频转化为离散 token,并统一使用 Transformer 进行训练,实现了多模态数据的整合。该模型能够在多个领域(图像、视频、文本)表现出色,并且可以同时处理这些不同模态的数据,适用于多模态任务。
- 无扩散、无组合架构:Emu3 的设计抛弃了传统的扩散模型和组合架构,专注于 token 预测。这种设计使得模型在训练和推理过程中能够更高效地扩展。减少了对传统复杂架构的依赖,提高了模型的可扩展性,适用于更多任务和更大规模的数据集。

Emu3的性能评测
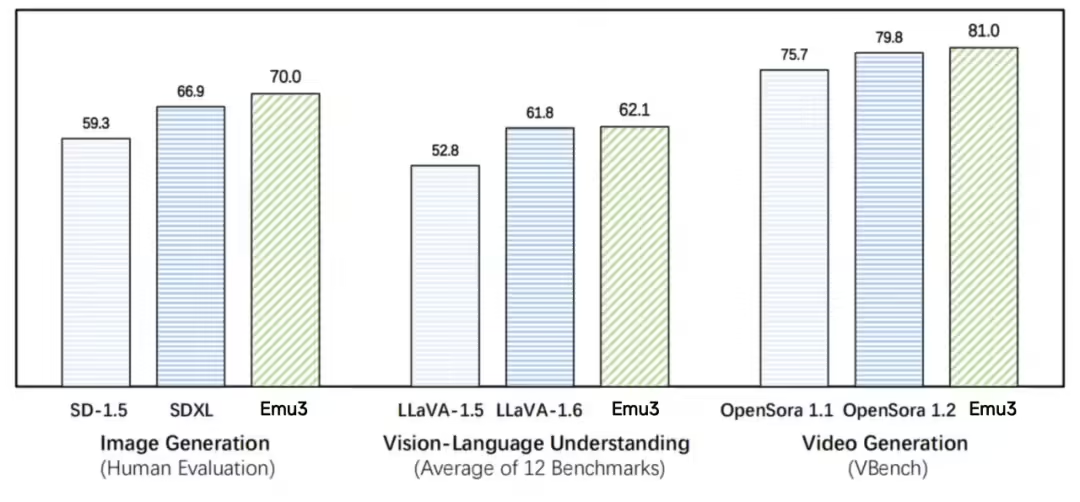
在图像生成任务中,基于人类偏好评测,Emu3 优于 SD-1.5 与 SDXL 模型。在视觉语言理解任务中,对于 12 项基准测试的平均得分,Emu3 优于 LlaVA-1.6。在视频生成任务中,对于 VBench 基准测试得分,Emu3 优于 OpenSora 1.2。
如何使用Emu3?
目前 Emu3 已开源了关键技术和模型,链接如下:
- Emu3 官网:https://emu.baai.ac.cn/
- Emu3 代码:https://github.com/baaivision/Emu3
- Emu3 模型:https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
