

CoDi是什么?
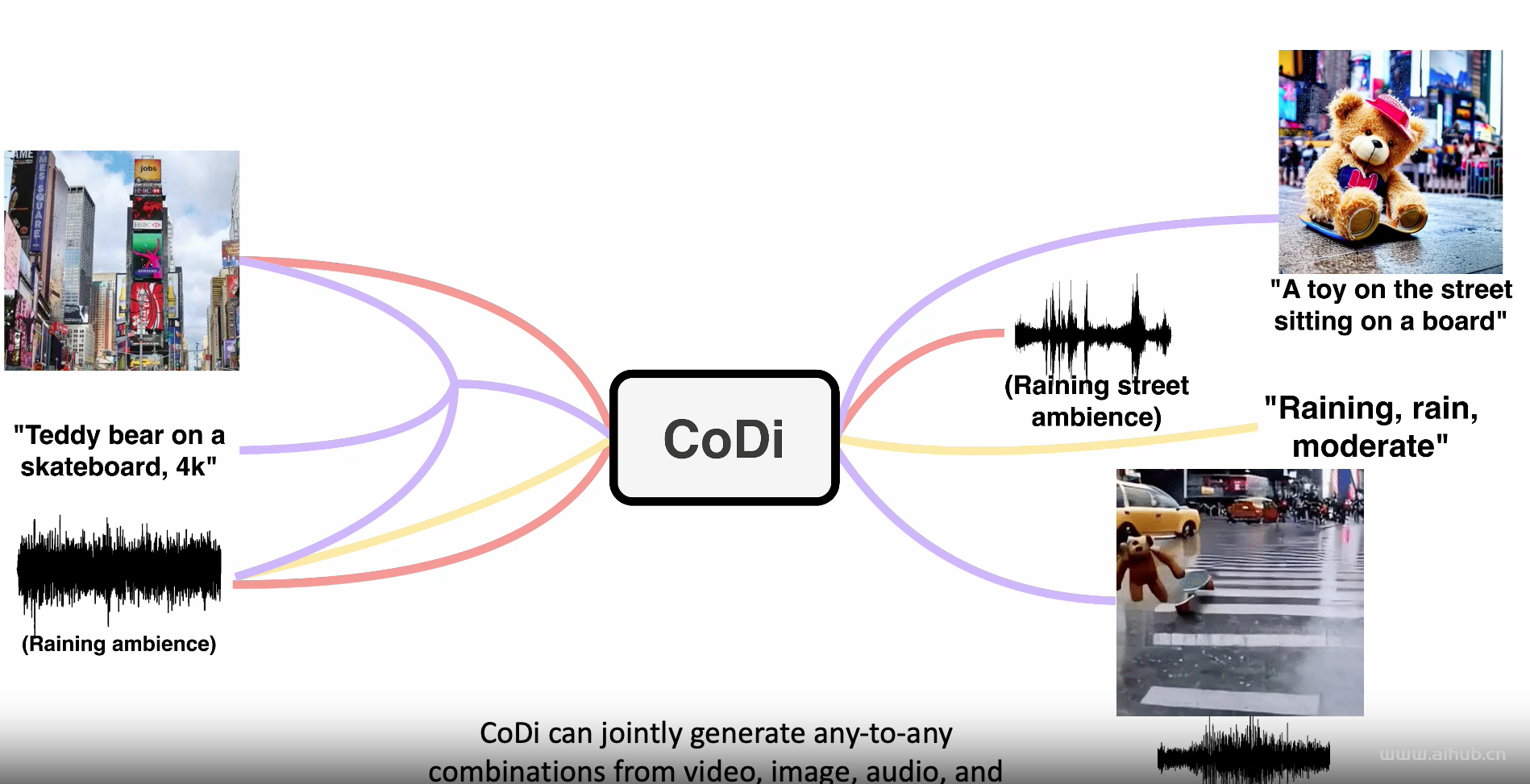
CoDi (Composable Diffusion) 是一个新颖的生成模型,能够从任何组合的输入模态(如语言、图像、视频或音频)生成任何组合的输出模态。
更多 demo 体验:https://codi-gen.github.io/
与现有的生成 AI 系统不同,CoDi 可以并行生成多种模态,其输入不仅限于文本或图像等子集模态。尽管许多模态组合的训练数据集不存在,但我们提出在输入和输出空间中对模态进行对齐。这使 CoDi 能够自由地根据任何输入组合进行条件设置,并生成任何模态组,即使它们在训练数据中不存在。CoDi 采用了一种新颖的可组合生成策略,该策略涉及通过在扩散过程中建立对齐来构建共享的多模态空间,从而实现交织模态(如时间对齐的视频和音频)的同步生成。CoDi 高度定制化和灵活,实现了强大的联合模态生成质量,并与单模态合成的最新技术相媲美或者在同等水平。
CoDi 的模型架构使用了多阶段训练方案,使其能够仅对线性数量的任务进行训练,但对所有输入和输出模态的组合进行推理。
CoDi 的使用示例包括:
- 多输出联合生成:模型接受单个或多个提示(包括视频、图像、文本或音频),生成多个对齐的输出,如伴有声音的视频。
- 多条件生成:模型接受多个输入(包括视频、图像、文本或音频)生成输出。
- 单对单生成:模型接受单个提示(包括视频、图像、文本或音频)生成单个输出。
如何使用?
CoDi 的研究论文已经发布在 arXiv 上,论文标题为 "Any-to-Any Generation via Composable Diffusion"。
论文地址:http://arxiv.org/abs/2305.11846
GitHub代码:https://github.com/microsoft/i-Code/tree/main/i-Code-V3
演示视频:

©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
