

BloombergGPT是什么?
根据彭博社最新发布的报告显示,其构建迄今为止最大的特定领域数据集,并训练了专门用于金融领域的LLM,开发了拥有500亿参数的语言模型——BloombergGPT。
报告显示,该模型依托彭博社的大量金融数据源,构建了一个3630亿个标签的数据集,支持金融行业内的各类任务。该模型在金融任务上的表现远超过现有模型,且在通用场景上的表现与现有模型也能一较高下。
一般来说,在NLP领域,参数数量和复杂程度之间具有正相关性,GPT-3.5模型的参数量为2000亿,GPT-3的参数量为1750亿。

这篇论文介绍了一种针对金融领域的大型语言模型BloombergGPT,并且探讨了其在金融业务应用中的潜在用途。BloombergGPT基于GPT-2和BERT模型,使用大量金融文本数据进行预训练。
BloombergGPT适合场景
作者认为,BloombergGPT可以应用于以下场景:
- 金融预测:BloombergGPT可以用于预测金融市场的趋势,例如股票价格、汇率等。
- 金融风险控制:BloombergGPT可以用于分析潜在的金融风险,并提供实时的警告和建议。
- 自然语言处理:BloombergGPT可以使用金融数据进行增强,从而提高自然语言处理的效果和准确率。
为了证明BloombergGPT在金融领域的有效性,作者进行了一系列实验。结果表明,BloombergGPT在生成下文、问答任务、文本分类等任务中,都表现出优异的性能。
总之,BloombergGPT是一种具有广泛潜在应用的大型语言模型,可以为金融界提供更加准确的预测、风险控制和自然语言处理服务。
标题:BloombergGPT: A Large Language Model for Finance
作者:Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, Gideon Mann
BloombergGPT优势
特定领域模型仍有其不可替代性且彭博数据来源可靠
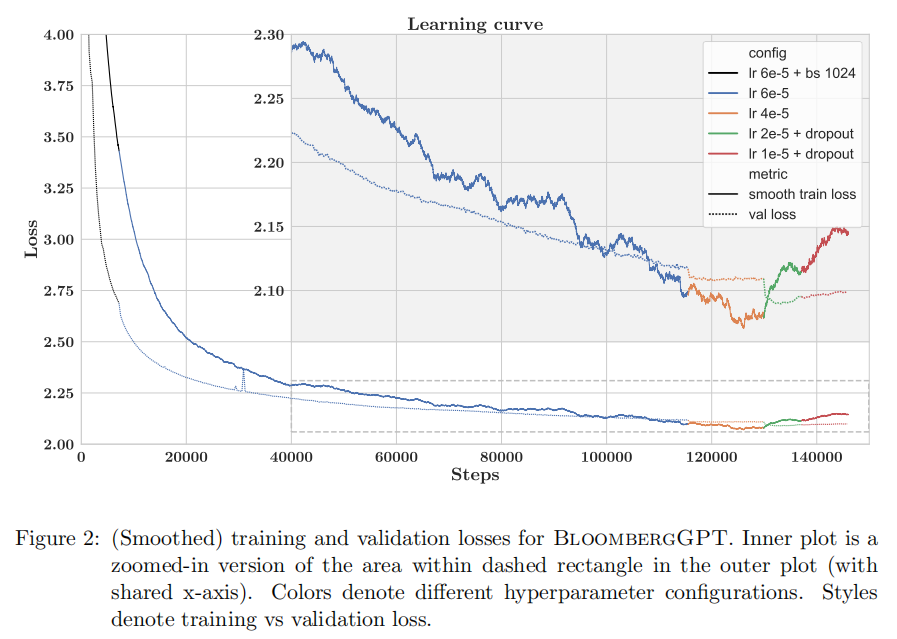
在论文中,彭博社指出,现阶段,通用的自然语言处理模型可以涵盖许多领域,但针对特定领域模型仍有其不可替代性,因彭博社的大多数应用均为金融领域,着手构建了一个针对金融领域的模型尤其优势,同时可以在通用LLM基准测试上保持竞争力:
除了构建金融领域的LLM外,本文的经验也为其他研究领域的专用模型提供了参考。我们的方法是在特定领域和一般数据源上训练LLM,以开发在特定领域和通用基准上表现优异的模型。
此外,我们的训练数据不同于传统的网络爬取数据,网络上的数据总有重复和错误,但我们的数据来源可靠。

BloombergGPT训练数据集
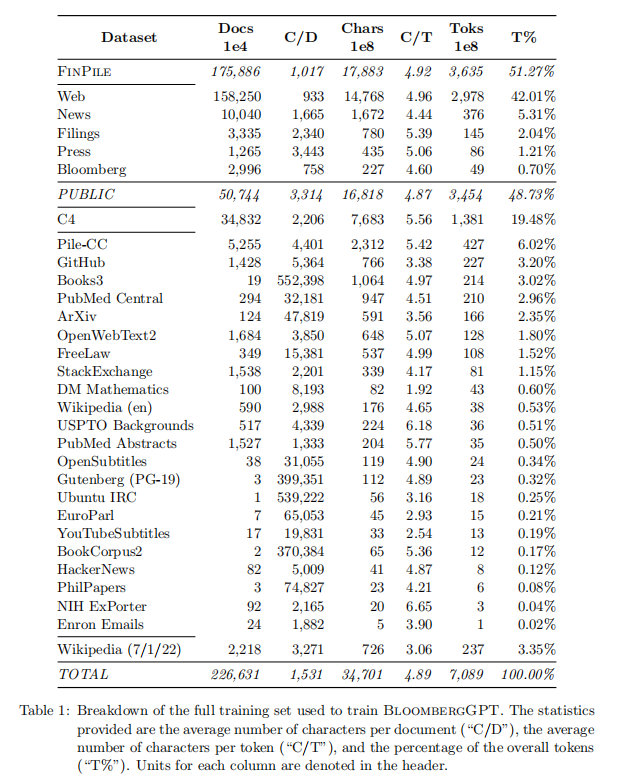
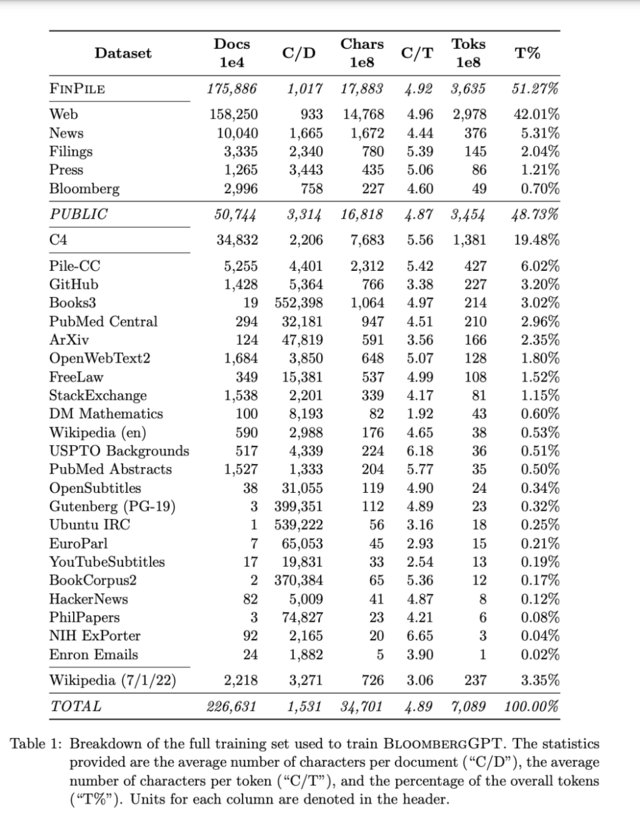
BloombergGPT的训练数据库名为FINPILE,由一系列英文金融信息组成,包括新闻、文件、新闻稿、网络爬取的金融文件以及提取到的社交媒体消息。
为了提高数据质量,FINPILE数据集也使用了公共数据集,例如The Pile、C4和Wikipedia。FINPILE的训练数据集中大约一半是特定领域的文本,一半是通用文本。为了提高数据质量,每个数据集都进行了去重处理。
对金融领域的理解更准
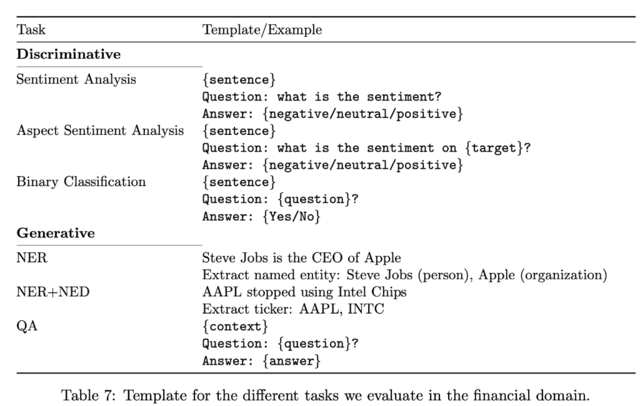
报告指出,在金融领域中的自然语言处理在通用模型中也很常见,但是,针对金融领域,这些任务执行时将面临挑战:
以情感分析为例,一个题为“某公司将裁员1万人”,在一般意义上表达了负面情感,但在金融情感方面,它有时可能被认为是积极的,因为它可能导致公司的股价或投资者信心增加。
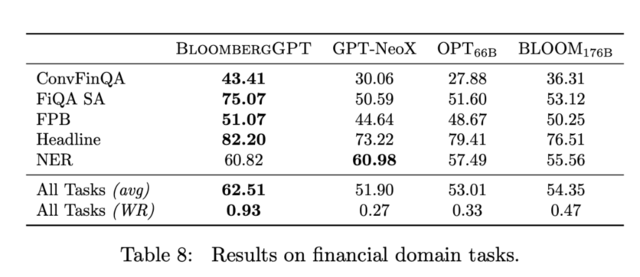
报告指出,从测试来看,BloombergGPT在五项任务中的四项(ConvFinQA,FiQA SA,FPB和Headline)表现最佳,在NER(Named Entity Recognition)中排名第二。因此,BloombergGPT有其优势性。
测试一:ConvFinQA数据集是一个针对金融领域的问答数据集,包括从新闻文章中提取出的问题和答案,旨在测试模型对金融领域相关问题的理解和推理能力。
测试二:FiQA SA,第二个情感分析任务,测试英语金融新闻和社交媒体标题中的情感走向。
测试三:标题,数据集包括关于黄金商品领域的英文新闻标题,标注了不同的子集。任务是判断新闻标题是否包含特定信息,例如价格上涨或价格下跌等。
测试四: FPB,金融短语库数据集包括来自金融新闻的句子情绪分类任务。
测试五:NER,命名实体识别任务,针对从提交给SEC的金融协议中收集金融数据,进行信用风险评估。
对于ConvFinQA来说,这个差距尤为显著,因为它需要使用对话式输入来对表格进行推理并生成答案,具有一定挑战性。
相关链接 https://wallstreetcn.com/articles/3685406#from=ios?ivk=1
