


DiffusionGPT是什么?
DiffusionGPT是一款由字节跳动和中山大学开发的文本到图像生成系统,它结合了大型语言模型(LLM)的能力和多个领域专家生成模型的优势。这个系统旨在处理各种输入提示,并选择最合适的模型来生成高质量的图像。DiffusionGPT通过构建基于先验知识的特定领域树结构,来引导模型的选择,从而能够在多个领域中实现卓越的性能。
DiffusionGPT工作原理
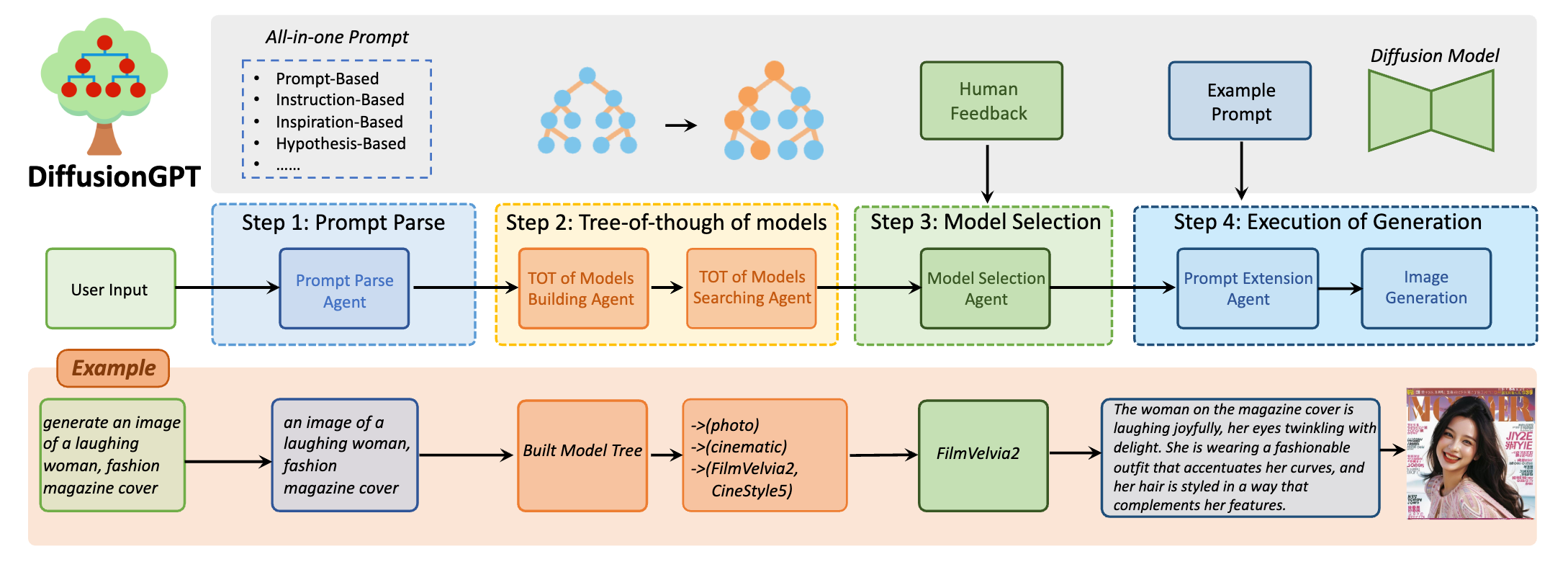
DiffusionGPT的工作原理涉及几个关键步骤:
- 提示解析:当用户输入一个文本提示时,DiffusionGPT使用大型语言模型(LLM)来解析这个提示。这个过程涉及理解提示的内容、意图和所需的图像风格或主题。
- 思维树构建:解析完提示后,LLM会构建一个“思维树”(Trees-of-Thought)。这个思维树是一种决策树,用于指导选择最合适的生成模型。它基于先前的知识和领域特定的信息来决定哪些模型最适合当前的提示。
- 模型选择:利用思维树,DiffusionGPT会从可能的候选模型中筛选出最佳选项。这个过程还涉及到人类反馈和优势数据库技术,以确保模型的选择与人类的偏好一致。
- 图像生成:一旦选择了最合适的模型,该模型就会使用核心提示来生成图像。这个过程可能包括多个迭代步骤,直到生成一个满足用户需求的图像。
总的来说,DiffusionGPT的工作原理是通过大型语言模型来理解和解析用户的文本提示,然后利用思维树来选择最佳的生成模型,并最终使用该模型生成与文本提示相匹配的图像。
DiffusionGPT适用人群
DiffusionGPT适合那些需要从文本提示生成高质量图像的用户,包括艺术家、设计师、营销人员和开发者。对于那些希望在不同领域中探索和实验图像合成的创意专业人士来说,DiffusionGPT提供了一个强大而灵活的工具。
如何使用DiffusionGPT?
项目地址:https://diffusiongpt.github.io/
论文:https://arxiv.org/abs/2401.10061
GitHub:https://github.com/DiffusionGPT/DiffusionGPT
在线体验地址:
- DiffusionGPT:https://huggingface.co/spaces/DiffusionGPT/DiffusionGPT
- DiffusionGPT-XL:https://huggingface.co/spaces/DiffusionGPT/DiffusionGPT-XL
©版权声明:如无特殊说明,本站所有内容均为AIHub.cn原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
