


AIHub获悉,11 月 8 日,阿里巴巴达摩院公布多模态大模型 M6 的最新进展,其模型参数已从万亿跃迁至 10 万亿,规模远超谷歌、微软发布的万亿级模型,成为目前全球最大的 AI 预训练模型。
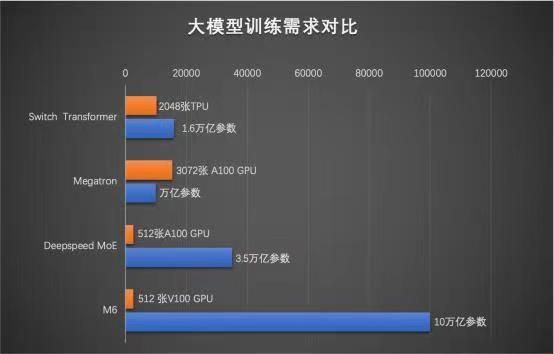
2021年以来,AI训练模型的规模不断扩大。据不完全统计,这些大模型包括年初华为发布的1000亿参数盘古大模型、1.6万亿参数的Google switch transformer模型、1.75万亿参数的智源悟道2.0智能模型、1.9万亿参数的快手精排模型等。其中,阿里达摩院M6模型上一次公布的参数规模为1万亿。
据了解,与传统AI相比,大模型拥有成百上千倍“神经元”数量,且预先学习过海量知识,表现出像人类一样“举一反三”的学习能力。因此,大模型被普遍认为是未来的“基础模型”,将成下一代AI基础设施。
“近年来人工智能的发展应该从家家户户‘大炼模型’的状态逐渐变为把资源汇聚起来,训练超大规模模型的阶段,通过设计先进的算法,整合尽可能多的数据,汇聚大量算力,集约化地训练大模型,供大量企业使用,这是必然趋势。”北京大学信息科学技术学院教授黄铁军说。
据报道,M6 做到了业内极致的低碳高效,使用 512 GPU 在 10 天内即训练出具有可用水平的 10 万亿模型。相比去年发布的大模型 GPT-3,M6 实现同等参数规模,能耗仅为其 1%。
据悉,M6 是达摩院研发的通用性人工智能大模型,拥有多模态、多任务能力,其认知和创造能力超越传统 AI,尤其擅长设计、写作、问答,在电商、制造业、文学艺术、科学研究等领域有广泛应用前景。
与传统 AI 相比,大模型拥有成百上千倍“神经元”数量,且预先学习过海量知识,表现出像人类一样“举一反三”的学习能力。因此,大模型被普遍认为是未来的“基础模型”,将成下一代 AI 基础设施。然而,其算力成本相当高昂,训练 1750 亿参数语言大模型 GPT-3 所需能耗,相当于汽车行驶地月往返距离。
今年 10 月,M6 再次突破业界极限,通过更细粒度的 CPU offload、共享-解除算法等创新技术,让收敛效率进一步提升 7 倍,这使得模型规模扩大 10 倍的情况下,能耗未显著增加.这一系列突破极大降低了大模型研究门槛,让一台机器训练出一个千亿模型成为可能。
今年,大模型首次支持双 11。M6 在犀牛智造为品牌设计的服饰已在淘宝上线;凭借流畅的写作能力,M6 正为天猫虚拟主播创作剧本;依靠多模态理解能力,M6 正在增进淘宝、支付宝等平台的搜索及内容认知精度。

M6生成的未来感汽车图
达摩院智能计算实验室负责人周靖人表示,“接下来,我们将深入研究大脑认知机理,致力于将M6的认知力提升至接近人类的水平,比如,通过模拟人类跨模态的知识抽取和理解方式,构建通用的人工智能算法底层框架;另一方面,不断增强M6在不同场景中的创造力,产生出色的应用价值。”
- Facebook正式改名Meta,扎克伯格All in元宇宙,开启新征程;
- 微软加入元宇宙大战:将Mesh直接植入Teams中,将不同元宇宙粘合起来;
- 中科深智完成B轮融资,利用AI技术打造元宇宙内容生产中台。
-
全球第一!阿里达摩院AI训练模型M6参数破10万亿,远超谷歌、微软; - 微软宣布推出Azure OpenAI服务,为开发者带来GPT-3模型,帮助企业建构更聪明的应用;
- 全球最大规模人工智能巨量模型 “源1.0”正式开源!2457 亿模型参数,超越美国GPT-3模型。
3.AI人物:

